The Rise of Token Expenditure
Why Persistent Inference is Reshaping AI Infrastructure
The artificial intelligence industry is entering a structural transition that most investors, operators, and enterprises still do not fully appreciate.
For the past several years, the dominant narrative in AI revolved around model training. The market rewarded larger GPU clusters, larger parameter counts, larger foundation models, and increasingly expensive pre-training runs. Competitive advantage appeared to belong to whoever could accumulate the most compute and train the most capable systems.
But a different economic layer is now beginning to emerge beneath the surface of the market.
That layer is token expenditure.
The next phase of AI infrastructure will not be defined primarily by training workloads. It will be defined by persistent inference demand generated by autonomous systems continuously performing computational labor.
This matters because inference behaves fundamentally differently than training.
Training is episodic. Inference is continuous.
Training workloads are centralized and periodic. Inference workloads increasingly operate as always-on systems embedded into enterprise software, industrial operations, autonomous vehicles, robotics platforms, coding agents, workflow orchestration systems, and persistent digital environments.
As AI moves from “question-answering software” toward operational infrastructure, token consumption begins scaling nonlinearly.
A single chatbot interaction may consume a few hundred or a few thousand tokens. An autonomous multi-agent workflow may consume millions. The difference between the two is not incremental. It is architectural.
This transition represents one of the most important economic shifts happening inside AI today.
From chat to computational labour
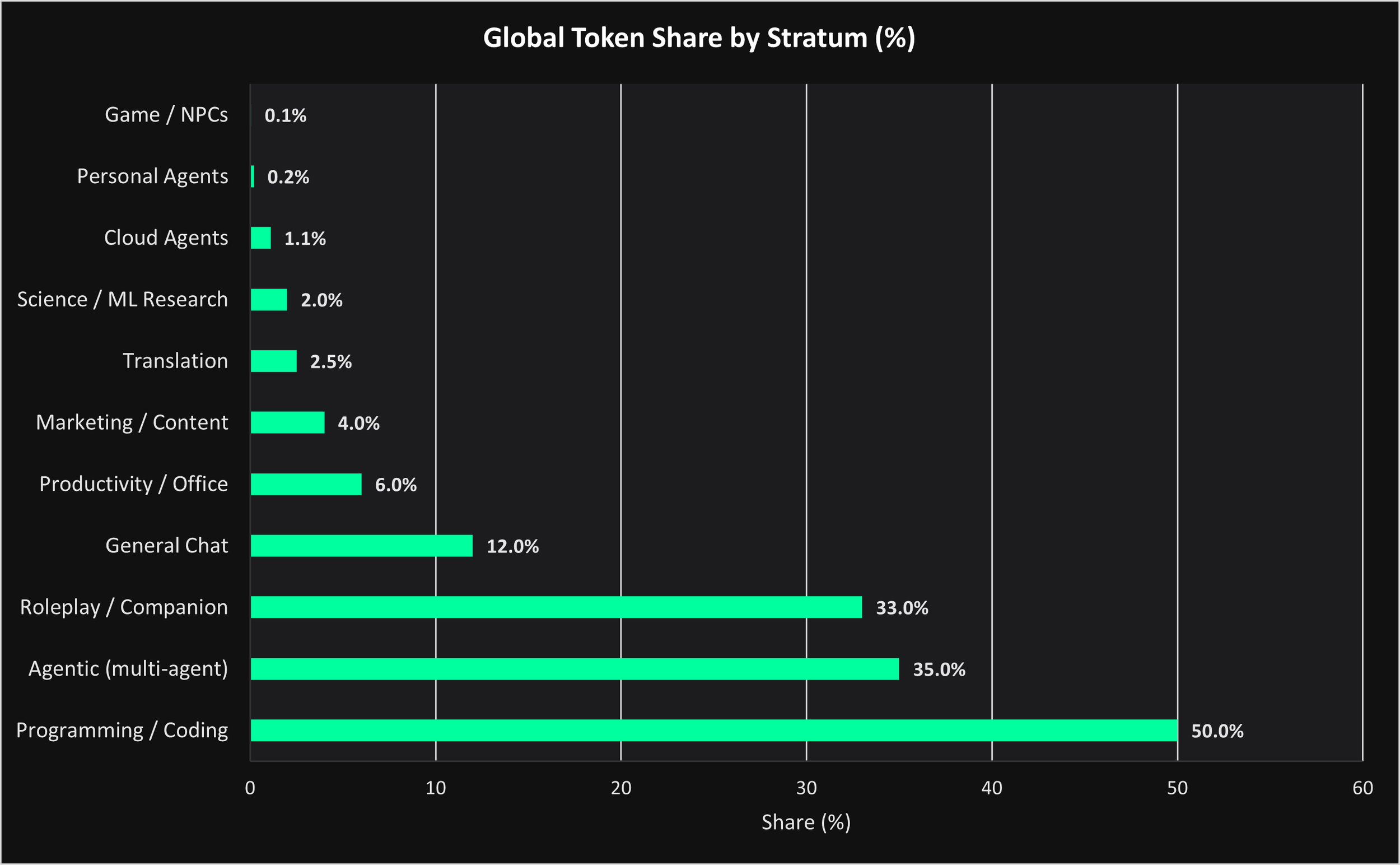
The first chart illustrates where global inference demand is already beginning to concentrate.
What immediately becomes clear is that traditional single-turn chat interfaces are no longer the dominant long-term workload category. Instead, coding systems, agentic workflows, and persistent companion systems are rapidly becoming the largest consumers of inference throughput.
Programming and coding workflows account for the largest share of token demand globally, followed closely by multi-agent orchestration systems and roleplay or persistent companion environments.
This is not accidental.
Coding systems naturally create recursive inference loops. A coding agent does not simply answer a question and terminate execution. It inspects repositories, generates plans, edits files, runs tests, interprets errors, retries failed execution paths, performs retrieval, updates documentation, and recursively expands chains of reasoning until objectives are completed.
Each layer of autonomy compounds token usage.
The same dynamic applies to enterprise orchestration systems. An enterprise agent operating across CRM systems, internal databases, Slack channels, procurement workflows, and financial software generates continuous inference activity rather than discrete interactions.
The important distinction is that these systems increasingly resemble machine employees rather than software tools.
The market is moving from conversational AI toward computational labor.
That distinction changes everything about infrastructure economics.
Token demand is becoming industrial
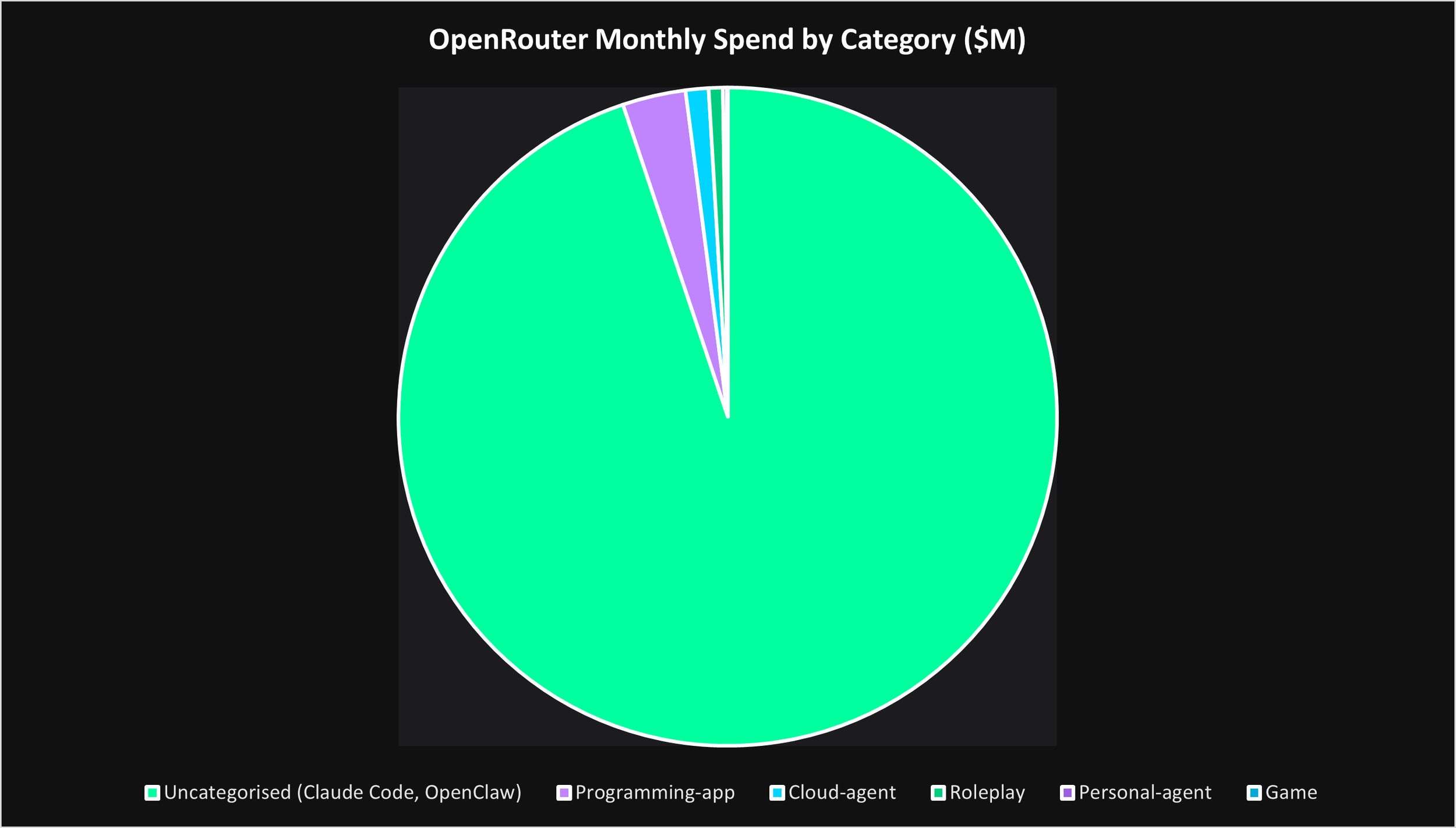
The second chart demonstrates how dramatically inference demand is already concentrating around coding-adjacent and uncategorized agentic workloads.
What is particularly important here is not simply the scale of consumption, but the structure of the demand itself.
Most of these workloads are persistent systems rather than temporary interactions.
Traditional cloud infrastructure evolved around bursty human behavior: opening applications, loading webpages, streaming content, or executing database requests. AI inference behaves differently because autonomous systems generate demand recursively.
An agent performing research invokes retrieval systems. Retrieval expands context windows. Expanded context triggers additional reasoning chains. Reasoning chains invoke tools. Tool outputs create new inference calls.
The system becomes self-propagating.
This creates an entirely different utilization profile for AI infrastructure.
Inference clusters increasingly resemble industrial production environments rather than traditional cloud servers. GPU utilization, concurrency optimization, routing efficiency, latency reduction, memory orchestration, and workload specialization become critical economic variables.
This is one of the reasons why inference economics are likely to diverge significantly from simplistic GPU leasing or raw compute commodity models over time.
The highest-value infrastructure operators may not be the companies with the largest clusters. They may instead be the companies that best understand computational logistics.
In other words, the future AI economy may reward those who optimize the movement of machine labor rather than simply owning compute supply.
Enterprise AI will multiply token expenditure
Today, most enterprises still interact with AI through relatively shallow interfaces.
Employees open copilots. Analysts query chat systems. Teams experiment with retrieval workflows. AI remains layered on top of existing organizational structures rather than embedded deeply within them.
That will not remain true.
The future enterprise is likely to operate persistent AI orchestration systems continuously across nearly every operational layer.
Procurement agents will negotiate supplier terms autonomously. Legal agents will review contracts in real time. Cybersecurity agents will monitor infrastructure continuously. Financial agents will reconcile accounts and forecast liquidity dynamically. Engineering agents will orchestrate development pipelines and software maintenance.
These systems will not operate occasionally.
They will run continuously.
This is where token expenditure becomes economically transformative.
A consumer chatbot generates intermittent demand. An enterprise operating thousands or millions of concurrent autonomous processes creates persistent computational load at industrial scale.
The result is that enterprise AI adoption may ultimately drive one of the largest infrastructure expansions in modern computing history.
Importantly, enterprise inference systems are also highly sensitive to latency and reliability.
As workflows become multi-agent and recursive, latency compounds across chains of reasoning. Every delay propagates downstream through the orchestration layer.
This creates increasing demand for geographically proximate inference infrastructure optimized for low latency, deterministic performance, and secure deployment environments.
The infrastructure requirements of enterprise AI increasingly resemble mission-critical industrial systems rather than generalized cloud computing.
Autonomous vehicles and robotics will explode token demand
The future state of token expenditure becomes even more dramatic when autonomous physical systems begin scaling globally.
Autonomous vehicles are fundamentally persistent inference environments.
A self-driving vehicle continuously orchestrates perception systems, motion prediction engines, sensor fusion layers, environmental simulation systems, planning architectures, safety monitors, route optimization systems, and long-horizon decision-making frameworks simultaneously.
Each subsystem generates ongoing inference demand.
And unlike consumer chat applications, these systems operate continuously in real time.
Now multiply this by millions of autonomous vehicles operating globally.
The inference demand profile becomes enormous.
The same dynamic applies to robotics.
Humanoid robotics, warehouse automation, industrial robotics, logistics systems, and embodied AI platforms all require continuous interaction with the physical world. Every visual frame, sensor input, environmental update, and motion-planning cycle becomes an inference event.
A humanoid robot working inside a warehouse or enterprise environment may consume continuous streams of visual tokens, spatial reasoning tokens, planning tokens, memory tokens, and action-generation tokens simultaneously.
This represents something much larger than software adoption.
It represents the emergence of machine labor operating directly inside the physical economy.
As robotics and autonomous systems scale, token expenditure increasingly maps directly onto economic production itself.
Tokens become the atomic unit of computational work.
The economics of persisted intelligence
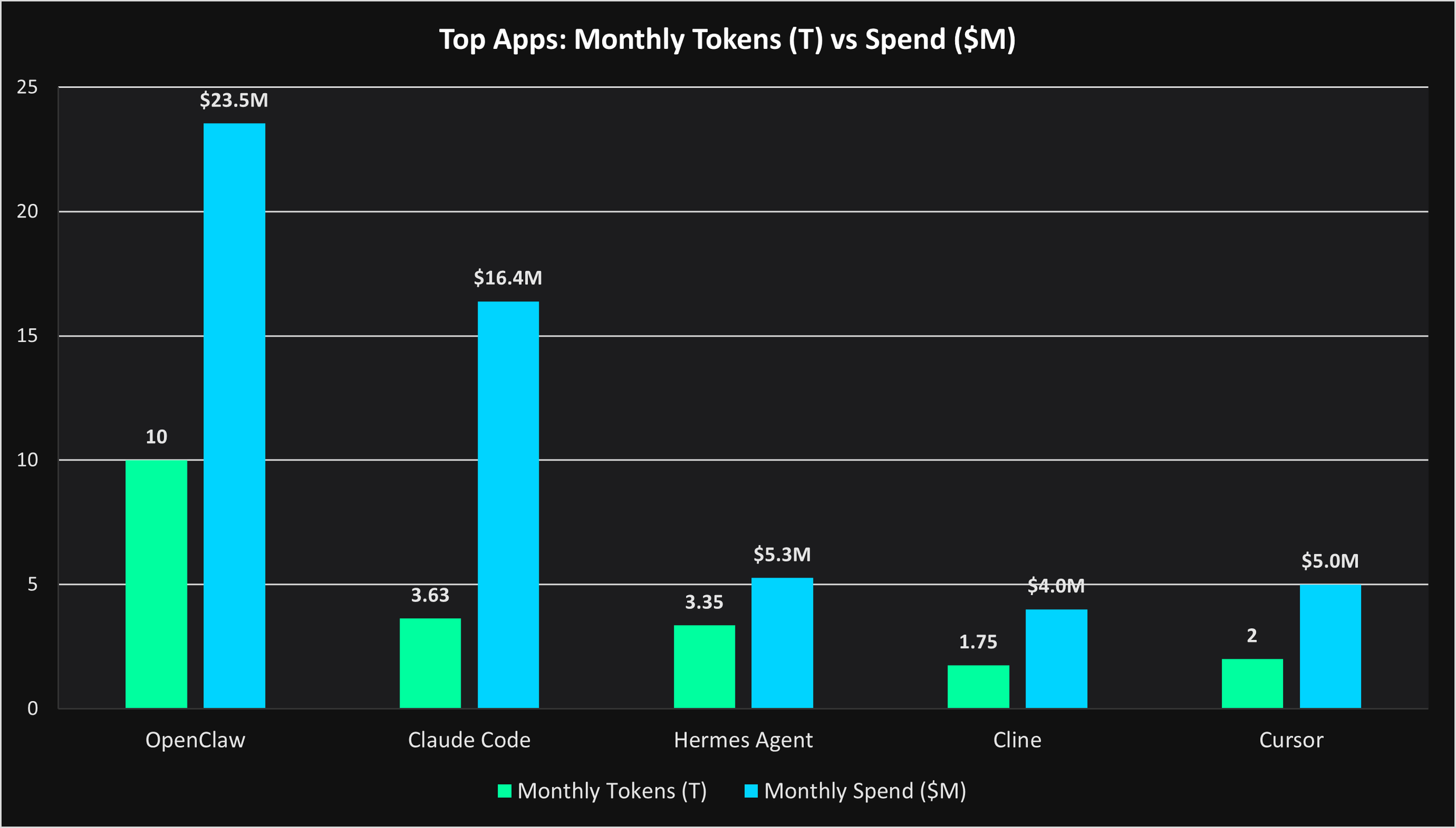
The third chart highlights an increasingly important signal: token demand is already becoming monetizable at meaningful scale.
Applications such as OpenClaw, Claude Code, Cursor, Cline, and Hermes Agent demonstrate that coding-native AI systems are generating both enormous throughput and substantial economic activity.
This matters because it validates that persistent inference systems are not merely technological experiments. They are emerging economic engines.
Importantly, these applications also reveal that not all token demand is economically equivalent.
Some workloads maximize throughput. Others maximize intelligence density.
Workload complexity changes everything
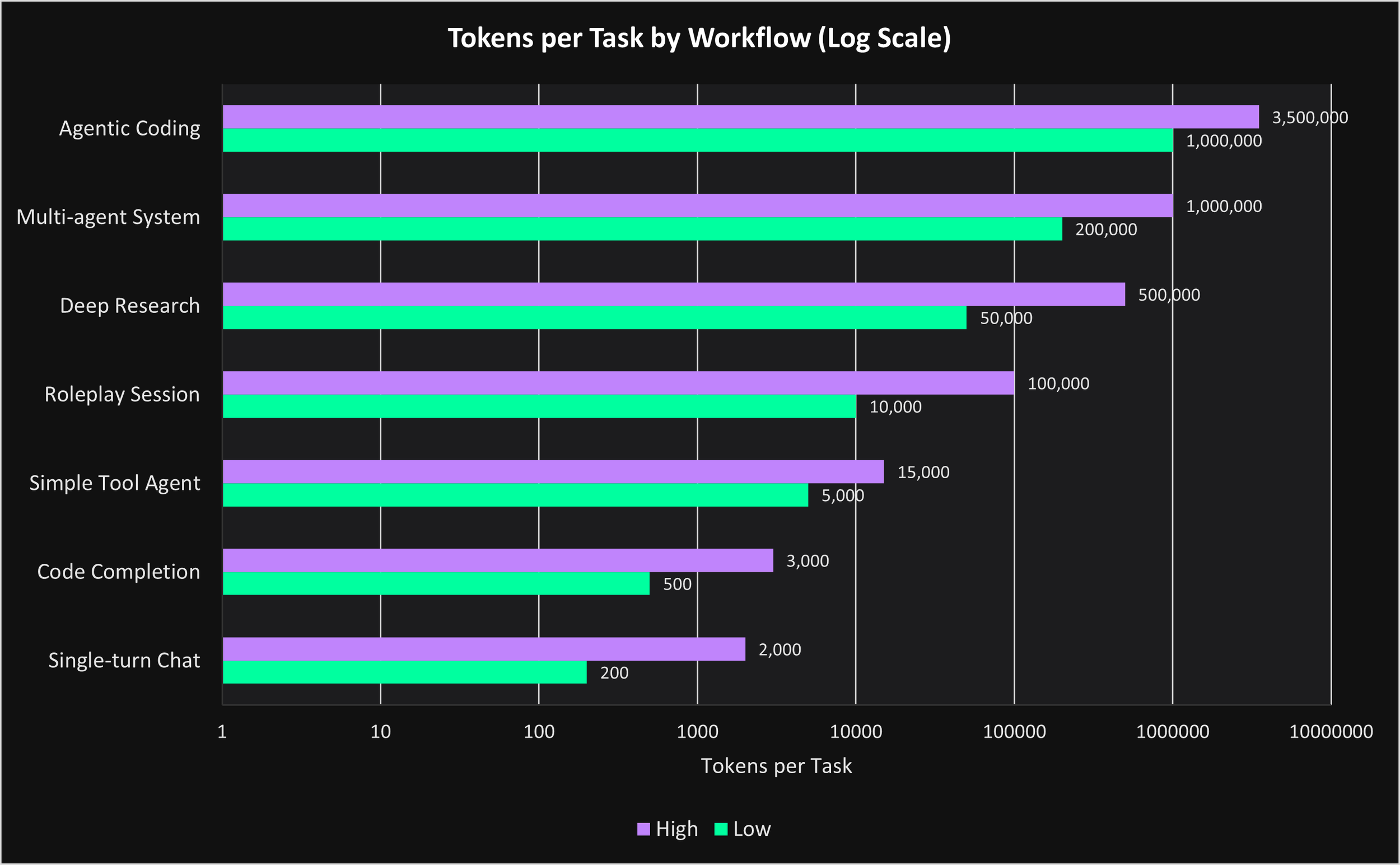
The fourth chart demonstrates how dramatically token consumption scales as workflows become increasingly autonomous.
A simple chat interaction may consume only a few hundred tokens. A coding completion workflow may consume several thousand. Deep research systems, roleplay environments, and multi-agent orchestration layers consume orders of magnitude more.
Agentic coding systems can consume millions of tokens within a single operational workflow.
This creates a future where infrastructure optimization becomes increasingly tied to both workflow architecture and raw hardware accumulation.
The winners in AI infrastructure may ultimately be the companies best able to sustain persistent computational workflows efficiently across highly autonomous systems.
The future of token pricing
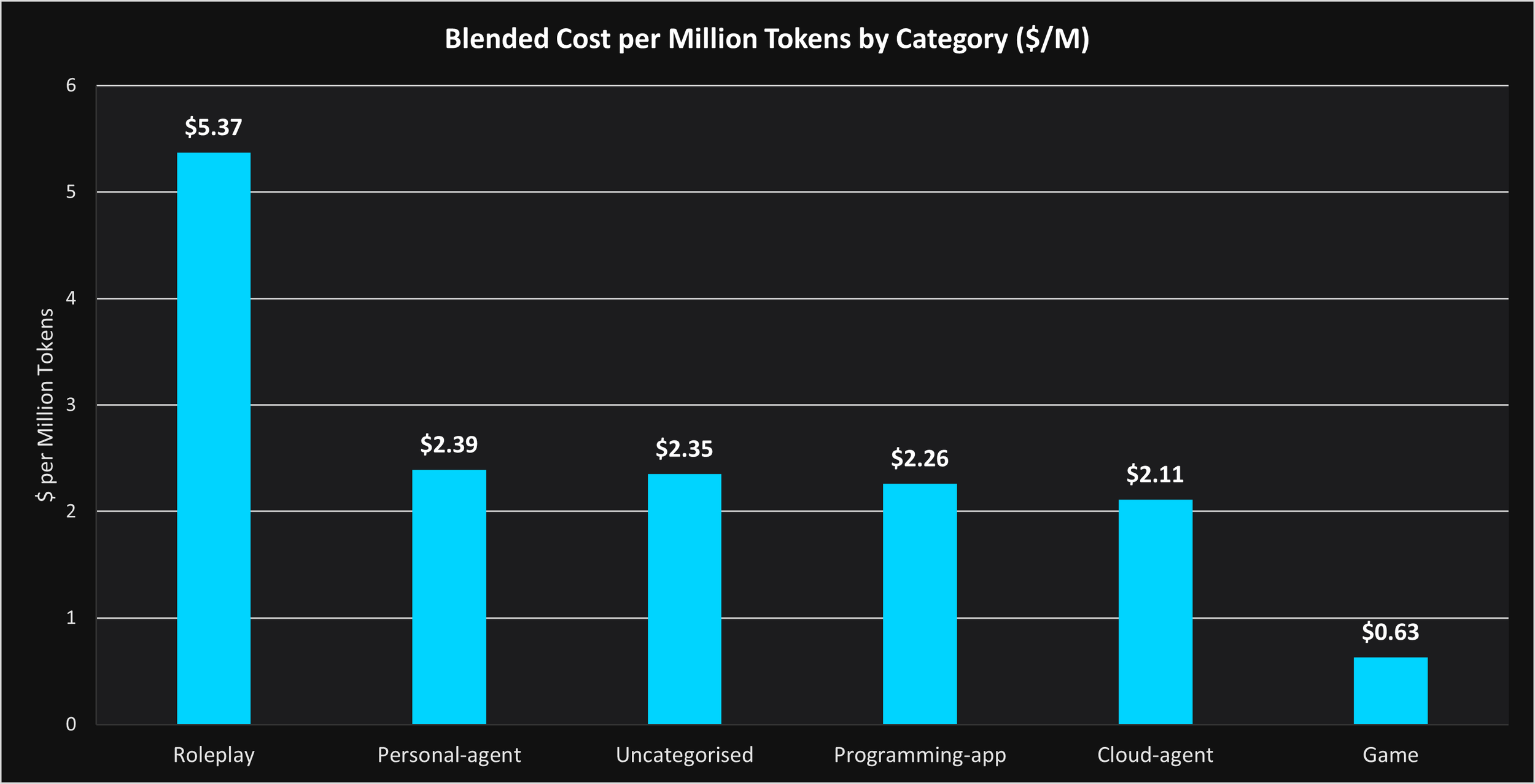
The final chart reveals another important dynamic: different categories of intelligence command different economic value.
Roleplay and emotionally persistent systems command premium pricing because they maximize engagement duration, memory persistence, and contextual continuity.
Coding systems generate massive aggregate throughput because recursive workflows continuously expand inference demand.
The AI economy is beginning to bifurcate into two dominant categories:
First, high-throughput machine labor systems such as coding agents, enterprise orchestration systems, robotics, and industrial AI.
Second, high-engagement persistent interaction systems such as companions, immersive environments, and emotionally persistent AI interfaces.
Both categories are inference-intensive. Both reward infrastructure optimized around sustained utilization rather than intermittent chat traffic. And both represent the beginning of a much larger transition.
Token expenditure as an economic signal
The next decade of AI infrastructure will be defined less by training clusters and more by persistent inference systems generating continuous computational labor.
The critical question is which systems generate sustained token expenditure at scale. Because token expenditure is increasingly becoming a proxy for autonomous economic activity itself.
The companies that understand this shift earliest (infrastructure operators, enterprises, developers, and investors alike) may ultimately control the next major layer of the AI economy.
Inference is becoming industrialized. And token expenditure is becoming the economic signal that matters.