Software & Silicon
Why Software, Not Silicon, Is NVIDIA’s Real Advantage
GPUs get the headlines, but in high-performance AI computing (especially inference), CUDA is the real engine of performance. The GPU hardware executes instructions; the CUDA software stack determines which instructions run, how they are scheduled, where data resides in memory, and whether the GPU runs at 40% or 95% utilization. Modern NVIDIA GPUs are inseparable from CUDA; you don’t simply buy an H100 or upcoming B200 GPU and “add” software later. Rather, you buy into a vertically integrated compute stack in which CUDA controls the full path from your Python code to silicon. This stack is what enables today’s top-tier AI inference performance.
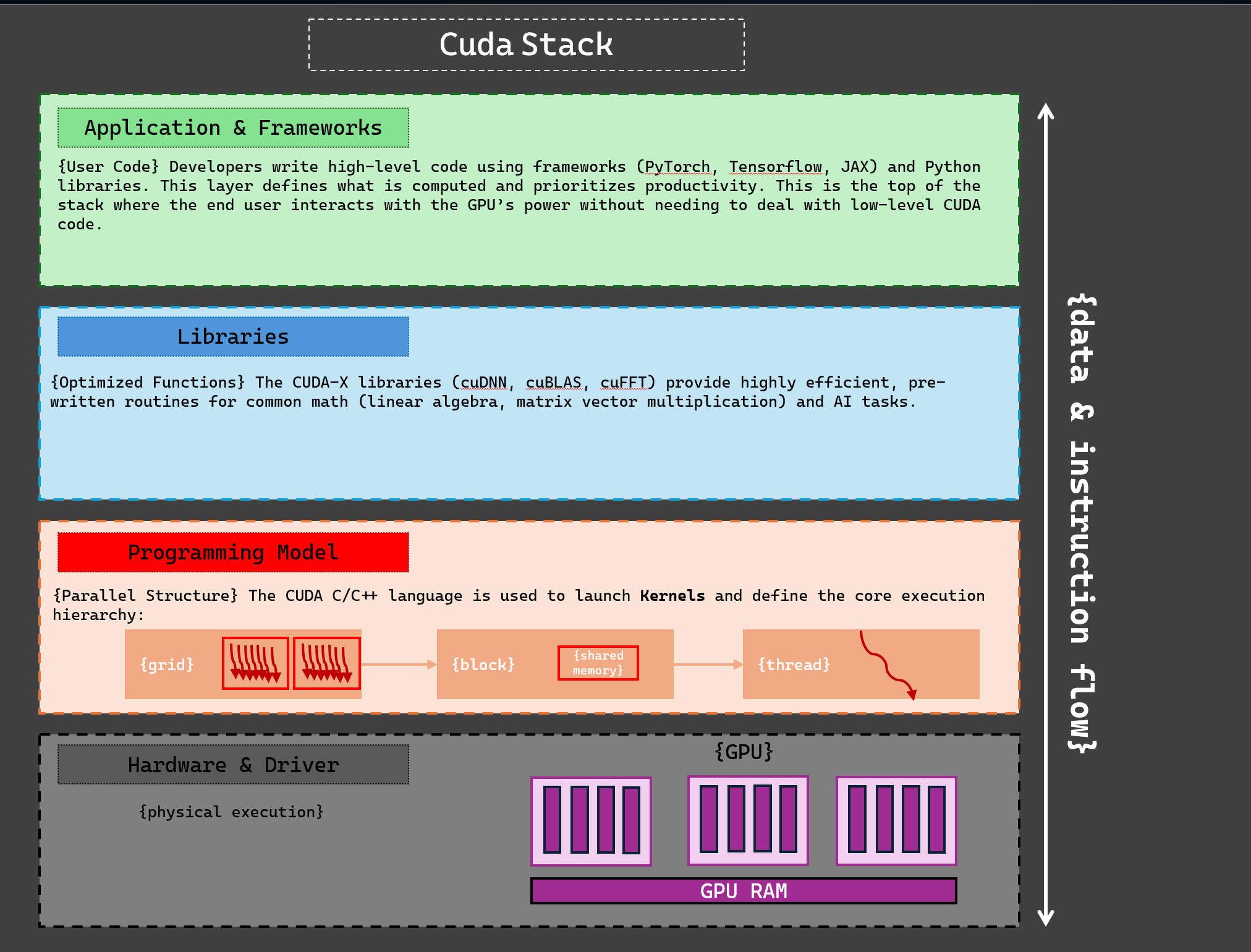
Figure: The NVIDIA CUDA stack is a layered system, from high-level AI frameworks down to low-level hardware. Each layer builds on the one below it to extract maximum performance. In practice, improvements at each layer compound together, making the whole system far more efficient than hardware alone could achieve.
Applications & Frameworks: Productivity Without Performance Sacrifice
At the top of the CUDA stack are the deep learning frameworks and applications that most developers use, for example, PyTorch, TensorFlow, JAX, OpenAI Triton, vLLM, and TensorRT-LLM. The key point is not just ease of use, but abstraction without performance sacrifice. Code written in Python at this level can still be optimized into efficient GPU operations. Thanks to CUDA’s support, high-level framework code can be:
Fused into large GPU kernels (to eliminate unnecessary launches)
Re-ordered for better memory locality and cache use
Optimized for tensor cores and lower precision (FP16/BF16/FP8/INT8) automatically
Scaled from 1 GPU to many GPUs without changes to the model code
-
It is a computer program that acts as the bridge or intermediary between the computer's hardware (CPU, RAM, hard drive, keyboard, etc.) and the software applications (web browser, games, word processor, etc.) you use.
This is possible because CUDA provides stable kernel semantics, predictable memory behavior, and a reliable compiler toolchain that frameworks trust. When PyTorch introduces features like torch.compile or JAX uses XLA to fuse an entire Transformer layer into a single kernel, they are leaning on CUDA’s guarantees about correctness and performance. The result is that software updates alone often bring significant speedups. For instance, performance gains users see are frequently delivered by new software releases on the same hardware, not just by new GPUs. In modern AI inference workloads, CUDA-backed frameworks have yielded throughput improvements on the same GPU generation over time via techniques like kernel fusion, smarter batching, and graph optimizations. In other words, a model might run multiple times faster after a year of framework and CUDA library updates, even if you haven’t upgraded the GPU itself.
CUDA-X Libraries: Where Most Performance Actually Comes From
Beneath the frameworks, the CUDA-X libraries (the “Libraries” layer in the diagram) are where NVIDIA quietly delivers a majority of the performance. Key libraries include:
cuBLAS: optimized dense linear algebra (matrix multiply, etc.)
cuDNN: deep neural network primitives (convolutions, recurrent cells, etc.)
cuFFT: fast Fourier transforms and signal processing routines
TensorRT: inference engine optimizations for neural networks (now including TensorRT-LLM for large language models)
NCCL: multi-GPU and multi-node communication (collective operations)
These libraries are not mere conveniences, they are hand-tuned, architecture-aware implementations written by NVIDIA’s own engineers who know the GPU topology intimately. The CUDA libraries will dynamically select the fastest kernel for a given operation based on factors like tensor shape and data type, and they rearrange memory layouts behind the scenes to maximize memory bandwidth and cache reuse. This tight coupling to the hardware is a big reason why GPU performance can improve even when the hardware remains the same. Each new CUDA Toolkit release typically brings further library optimizations.
For example, NVIDIA’s updates to cuDNN often yield double-digit percentage speedups for existing models with no changes to hardware. The recent cuDNN 9 release introduced support for advanced “flash” attention and FP8 precision, enabling about a 1.15x training speedup for a Llama-2 70B model simply by using the new library on the same GPUs. Likewise, the TensorRT-LLM library (part of NVIDIA’s TensorRT) can dramatically reduce inference latency for large language models, Amazon found that adding TensorRT-LLM cut Llama-2 and Falcon model latencies by ~33% on average and boosted throughput ~60% on the same hardware. These gains come from techniques like layer fusion, quantization, and execution re-ordering that are implemented at the library level. Meanwhile, the NCCL library enables near-linear scaling across multiple GPUs by efficiently overlapping communication with computation. It provides low-latency, high-bandwidth collectives that let AI workloads scale from a few GPUs in one server to thousands of GPUs in a cluster.
CUDA Programming Model: Grid–Block–Thread as a Performance Contract
The CUDA programming model, launching kernels as grids of thread blocks with an on-chip shared memory for each block, is not just a convenient abstraction. It’s essentially a performance contract between software and hardware. CUDA exposes explicit control over parallelism and memory hierarchy to the developer, along with deterministic execution behavior. In practice, even if most developers never write raw CUDA C++ code, this model underpins everything above it. Framework kernels, Triton code, and TensorRT engine plans all compile down to grids of thread blocks running on streaming multiprocessors.
One of CUDA’s most powerful features is shared memory (the programmer-managed scratchpad in each thread block). Using shared memory, developers or compilers can tile computations to reuse data without repeatedly accessing slower global memory. This enables manual optimizations (such as blocking matrix multiplications) that significantly increase adequate memory bandwidth and hide latency. The consistent grid/block/thread model and memory hierarchy make kernel performance predictable and tunable: performance bottlenecks can be identified with profilers and addressed by adjusting block sizes, memory access patterns, and related parameters. In effect, CUDA’s model ensures that software optimizations translate reliably into actual speedups on GPU hardware. This predictability (in contrast to fully black-box or opaque scheduling models) is a key reason CUDA remains the dominant choice in HPC environments where regression is unacceptable. Developers know that a well-written CUDA kernel will execute with deterministic parallel behaviour, which is crucial for both debugging and performance tuning in scientific computing.
Hardware & Drivers: CUDA Turns Silicon into a Full System
At the bottom of the stack are the GPU hardware components: SMs (streaming multiprocessors), tensor cores, memory controllers with HBM memory, NVLink interconnects, etc. On paper, GPUs from different vendors might have similar raw specs (FLOPs, memory size, bandwidth). In practice, however, the CUDA software (especially the driver and runtime) determines how the silicon is utilized within the system. CUDA governs low-level details like how memory is addressed and migrated, how work is scheduled across SMs, how data is transferred between GPUs or nodes, and how failures are handled in a large cluster.
Notably, NVIDIA’s software stack often exposes new hardware capabilities early and makes them usable for real workloads. For example, CUDA introduced GPUDirect RDMA (direct GPU-to-NIC DMA) back in the Kepler GPU days (CUDA 5.0), allowing GPUs to communicate over InfiniBand without extra copies. NVIDIA also rolled out Unified Memory (with automated page migration and prefetching) to simplify memory management across CPU-GPU, and features like NVLink and NVSwitch are tightly integrated such that multiple GPUs can behave like one memory space in multi-GPU servers. The CUDA driver’s support for graphs and asynchronous execution, multi-GPU collective communication, and advanced memory topology means that in large-scale inference (think serving an LLM across many GPUs), the software can orchestrate work far more efficiently. Inference on large models is often memory-bound, latency-sensitive, and communication-heavy, exactly the scenario where CUDA’s full-stack integration pays off. NVIDIA’s software knows how to utilize high-bandwidth NVLink/NVSwitch connections for model sharding, overlap communication with computation (e.g. using CUDA streams and NCCL), and manage scheduling so that GPUs spend less time idle waiting on data. This leads to faster token generation and lower tail latencies in practice, especially at scale. Indeed, the same model on the same GPU can run materially faster after a few CUDA driver and library updates, simply because the stack has learned to better optimize data movement and execution order.
CUDA Is the Performance Multiplier
CUDA is often described as “NVIDIA’s moat,” but that understates it. CUDA is not just one thing, it’s a production-grade compiler toolchain, a runtime environment, a rich ecosystem of math libraries, a distributed computing framework, and an ongoing R&D engine for performance. The GPU hardware provides the ceiling for performance, but CUDA largely determines how close you can get to that ceiling in real workloads. In high-performance AI inference, where throughput, latency, and ability to scale directly translate to economic value, CUDA is not optional or secondary; it is the decisive factor that makes the GPU’s compute power usable.
A modern NVIDIA GPU really operates at peak potential only because of CUDA. All the pieces of the stack work in concert to multiply performance. Hardware alone might give you theoretical FLOPs, but CUDA’s software stack ensures those FLOPs translate into actual useful work on your application. This is why an H100 GPU in a CUDA environment is often worth more (in terms of realized performance) than a theoretically similar processor without such a software ecosystem.
Impact on Compute Economics: Tokens per Watt-Dollar
All of these CUDA-driven performance gains have a direct impact on AI compute economics, often measured in terms of cost per inference or cost per output token. As one industry analysis put it, “Tokens are the basic unit of cost in AI. Total operational cost is simply tokens served X cost per token. Throughput drives profitability.” In practical terms, better utilization and higher efficiency from CUDA means you get more generated tokens per second for the same power and hardware cost (i.e. more tokens per watt and more tokens per dollar invested). If an optimization doubles the throughput on your existing GPU, it effectively halves the cost-per-token (since each GPU can serve twice as many tokens in the same time) and likewise improves energy efficiency (twice the tokens for the same energy consumption).
NVIDIA’s tight integration of software and hardware has markedly improved this tokens-per-watt-dollar metric over time. For example, the jump from the A100 GPU to the H100 GPU delivered about 10X higher throughput for only a roughly 2x increase in cost, significantly reducing the cost per inference. Each new hardware generation improves this further, the Blackwell GPUs (B200 series) will push the envelope again on performance per watt and per dollar. Crucially, CUDA’s software advances amplify these gains even on the same hardware. A striking recent example: NVIDIA demonstrated up to a 5.6x increase in Llama-2 model performance on the same H100 GPUs just by applying new TensorRT-LLM optimizations in the inference loop. In other words, through a software update, one H100 could do the work that previously took several H100s, a huge boost in tokens per dollar spent. Similarly, independent testing has shown that modern Hopper-generation GPUs running the latest CUDA stack can achieve dramatically better energy efficiency than a few years ago. This reflects both hardware improvements and the cumulative effect of CUDA optimizations (like better kernel algorithms and memory management).
From a business perspective, these improvements mean AI services can deliver more results (more tokens) with fewer GPUs and less power, directly improving profitability. An older GPU might run a given model. Still, as NVIDIA’s CEO Jensen Huang has noted, it might do so at a cost or power draw you “can’t economically defend” once a new generation or new software optimizations are available. A system running outdated hardware or lacking CUDA’s latest libraries will burn more power, produce fewer tokens per watt, and ultimately force higher inference costs to achieve the same output. In contrast, a system fully optimized with CUDA will squeeze near-maximum throughput out of each GPU, minimizing the cost per token. In the AI era, where inference volume is exploding, this is critical the difference between 40% GPU utilization and 95% utilization can make or break the economics of an AI product.
CUDA is not just a moat it’s a performance multiplier that directly improves the core efficiency metric of AI inference (tokens per watt-dollar). By vertically integrating software with silicon, NVIDIA ensures that each generation of GPUs, and even each software update, pushes the cost-per-token down and the throughput per dollar up. In a world where AI “runs on unit economics,” CUDA’s role in driving those unit economics is what truly makes NVIDIA’s GPUs worth buying. The GPU provides the raw muscle, but CUDA determines how effectively that muscle is flexed and thus how economically you can generate intelligence from silicon.